 MockMotor
MockMotor

Vladimir Dyuzhev
MockMotor Creator
How to Test Client Retries Against Unstable API
Implement periodic mock API failures to test client retries logic and performance
What are Client Retries?
Some API clients have a built-in retry logic to guarantee message delivery. Those guarantees are called “at least once” or “once and only once.”
On the client-side, it goes like this:
- Save the message into a persistent store (a file or a queue).
- Try to send it to the backend.
- Successful? Great, remove it from the store and move on.
- Failed? OK, retry the same message again after some time.
This is a very useful and widespread approach, but we need to simulate the API failure to test that it is implemented correctly and efficiently.
Functional Testing: Does it Work?
With functional testing, we try to prove that the client does redeliver the messages once a transient error between it and the API happens.
This test is not so easy to perform.
The testers usually have to disable the API manually, perform the test and then enable it back, all the way monitoring the logs to see if the message got delivered. This approach is not always possible because the same API can serve other requests, and the flow may not even reach the message sending if the whole API is down.
However, using a mock service - either as the final destination or as a proxy - makes it all very manageable.
Using Mock to Simulate Failures
Suppose we want to test a 25% failure rate in the used API. Let the failure be any HTTP 500 response (you can configure any other condition).
What we need to do is, before checking all our normal mock responses, try to match a special failure response. It matches randomly, using values outside of the
incoming request - for example, the random value from the mockmeta variable. We place it first on the list as a guard.
Now every request has to try and match itself against that failure mock.
When the failure mock doesn’t match (“API didn’t fail” case), the request moves on to the next mock response and eventually find the right match.
When the failure mock does match, the search for match ends and the mock service responds with an error (“API failed” case).
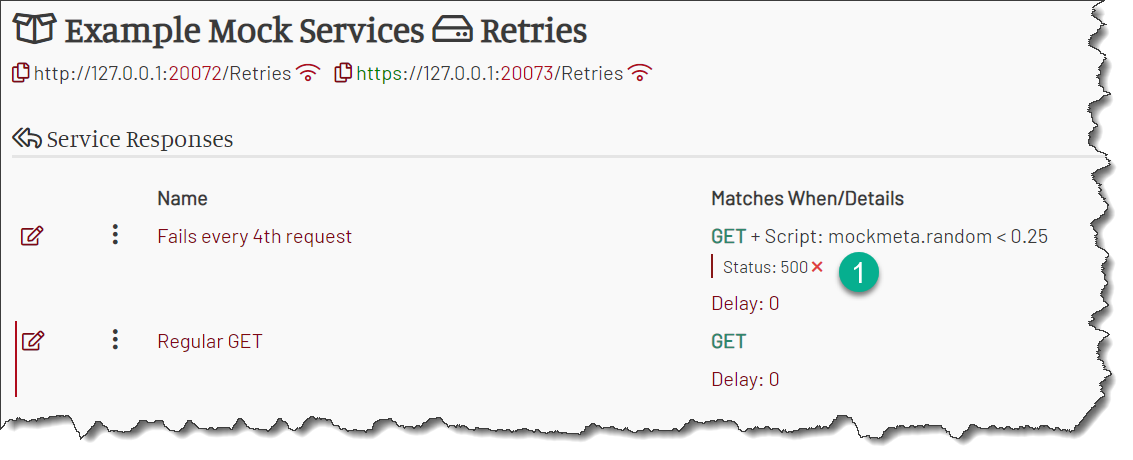
For example, the below service handles a single operation HTTP GET. However, the business mock Regular GET is guarded by a failure mock. That mock has a condition
mockmeta.random < 0.25. The random value in mockmeta is in the range from 0.0 to 1.0, so about 25% of all requests will have it below 0.25. That 25% of requests
fail, simulating a 25% failure rate in the service.
Now you just need to check the client or mock environment logs to see if the failed requests are retried until successful.
Of course, you don’t have to match all the requests for failure mock. You can make the failure mock react only to a specific operation or even a specific account in the payload, thus narrowing your test scenarios as much as you need.
Using Mock to Inject Failures for a Real API
But maybe you need to call a live API but still want to test the retries.
MockMotor can help you with that as well, serving as a proxy between the client and the API.
You set up a forwarding response in MockMotor. That response sends all the requests to the actual API and delivers the responses to the client code.
Then you add a failure mock response in front of it, the same way as in the previous section. However, now the successful calls are handled by the real API. MockMotor only injects the configured failure rate in the flow.
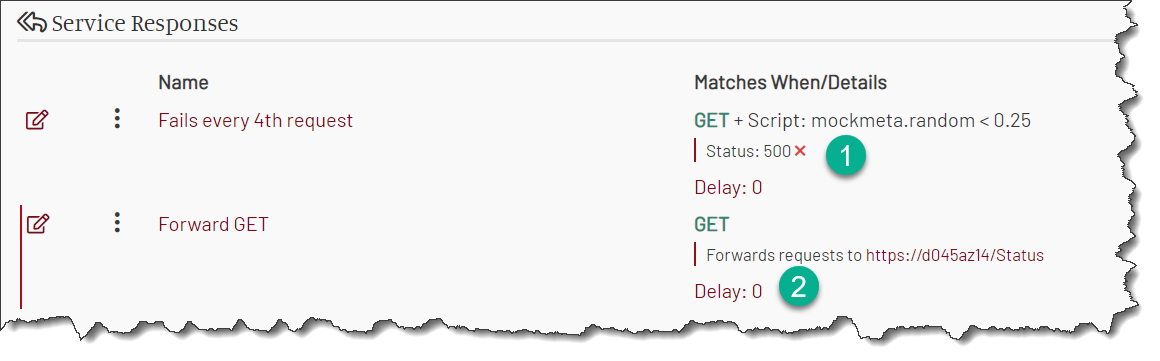
This way, you can test the retries even in DIT or SIT and still keep the test scenarios valid.
Performance Testing: Does it Get Slow?
What if the API is down for an extended time? The client begins to accumulate the messages, potentially growing its in-memory size. More messages need to be retried, more threads need to be used, more connections have to be created.
How our client behaves under these conditions? Will it survive? Will it recover when the API is back?
To answer these questions, we should run a performance test where API comes down and then, after some time, comes back up.
Just like with functional testing, it is not easy to set up such a test, especially in a repeatable way where the timing and duration of the downtime can be repeated in future runs.
MockMotor can help with that as well.
Down Then Up Then Down Then Up
Imagine we want the API to have periodic downtimes.
Every 5 minutes, it goes into a failure mode with increased RT and HTTP 500 status. After a minute, it comes back to norm and works well for another 5 minutes.
A simple random response doesn’t cut it anymore. Now we need to maintain a state which defines if the API is currently down or up.
The state in MockMotor is stored in a mock account. That account should have two properties: downTime is the time when the service must come down,
and upTime when the service should come back up. Suppose now is 9:05. Our downTime property should then contain 9:10 value, and upTime contains 9:11.
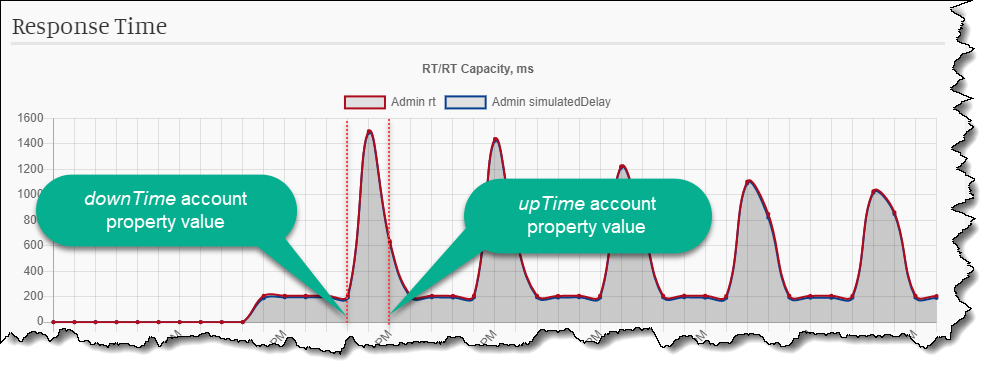
(The response time goes up when the service is unavailable and goes back to normal low values when it is available, so the graph looks upside down. :-) )
The mock service logic should check the current time and compare it with the values from the account:
- If the current time is before
downTime, the service responds in the normal way - either from mock responses or from the forward. - If the current time is after
downTime, but beforeupTime, the mock service should respond with HTTP 500 and RT 5s. - Once the current time is after
upTime, a dedicated response should set the newdownTimeandupTimevalues, five and six minutes in future.
Let’s configure that.
First, Create a Service State Account
We need to have two properties, downTime and upTime. Let’s create them.
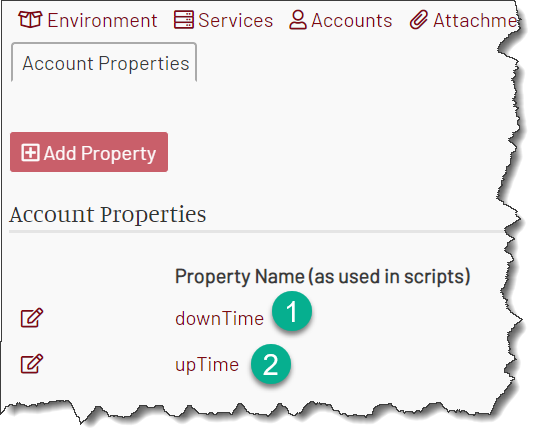
Now let’s create a mock account with those properties. The properties are going to store the time “since epoch” in milliseconds because it is easy to compare to mockmeta.epochMs variable.
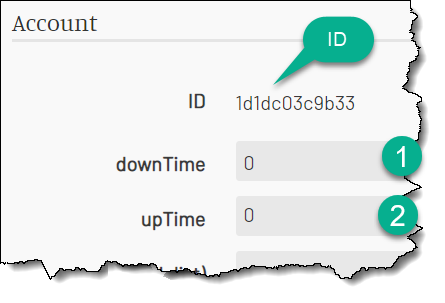
Put 0 into each of the fields.
Copy the account ID. We’ll need it to read the values in the responses.
Second, Create the Down Response
The down response matches any request when the current time is between downTime and upTime.
The current time is set to the variable mockmeta.epochMs available to every request. The match condition then is (if we use JS scripting):
mockmeta.epochMs > account.downTime && mockmeta.epochMs < account.upTime
We should put this expression into the Script match field. This expression uses the account, so we have to select the account using the account ID.
Finally, we should return some reasonable error payload and set the HTTP status to 500.
Here you go:
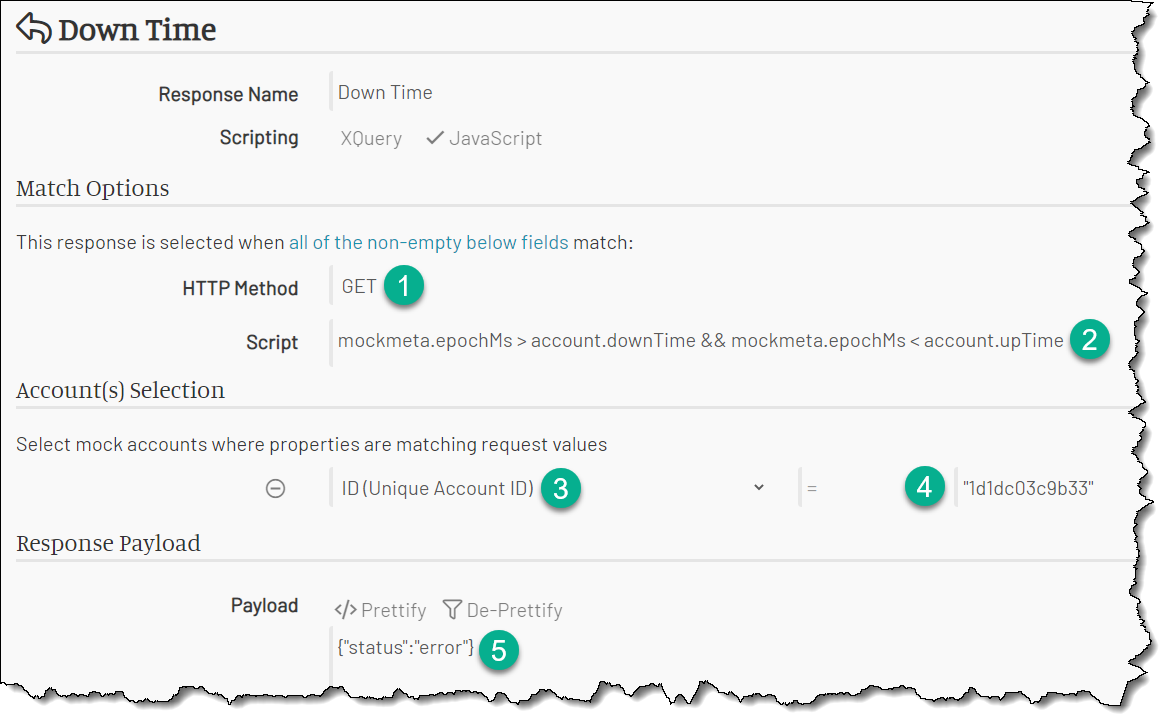
Finally, Create the Init Response
This response is matched when the current time is after the upTime. At that point, we should schedule our next downTime and upTime.
The script match condition is “we’re after the upTime”:
mockmeta.epochMs > account.upTime
The account is selected using the account ID, just like in the downtime response.
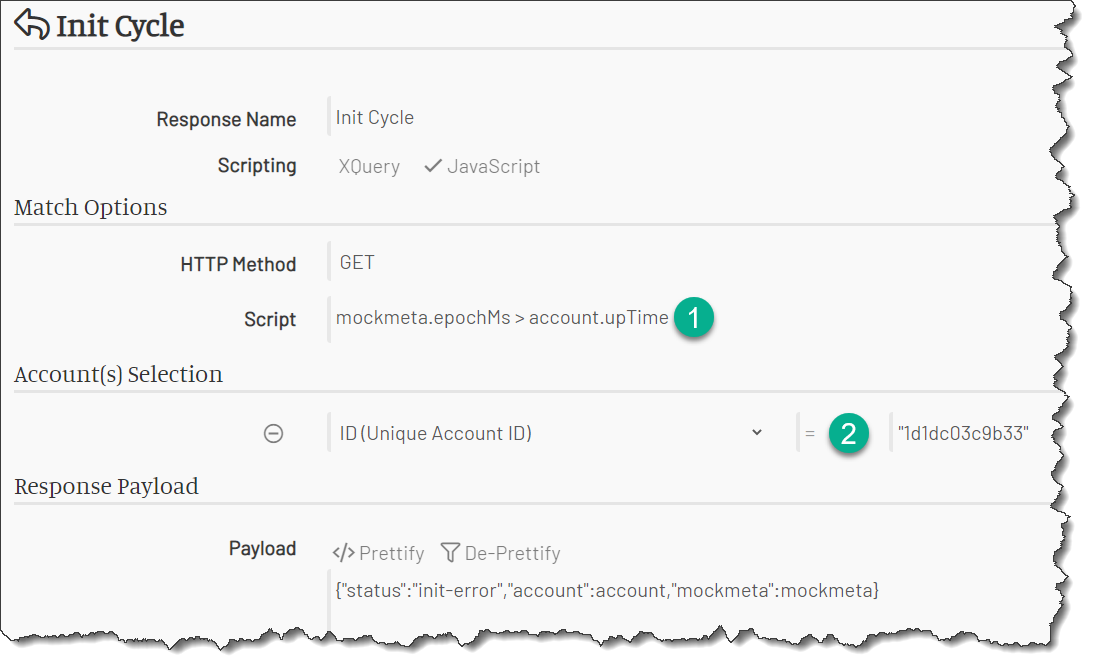
The response sets the mock account’s properties five and six minutes in future:
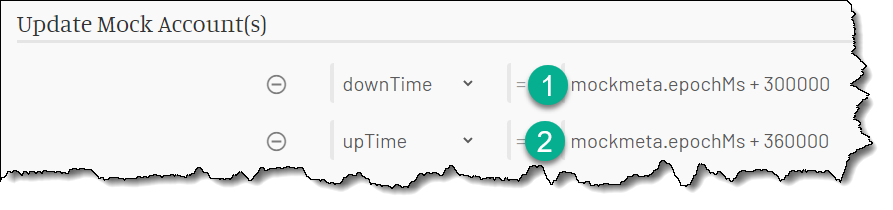
After this response, the service is back in the up mode (the current time is before the downTime value) and remains in that mode for another five minutes.
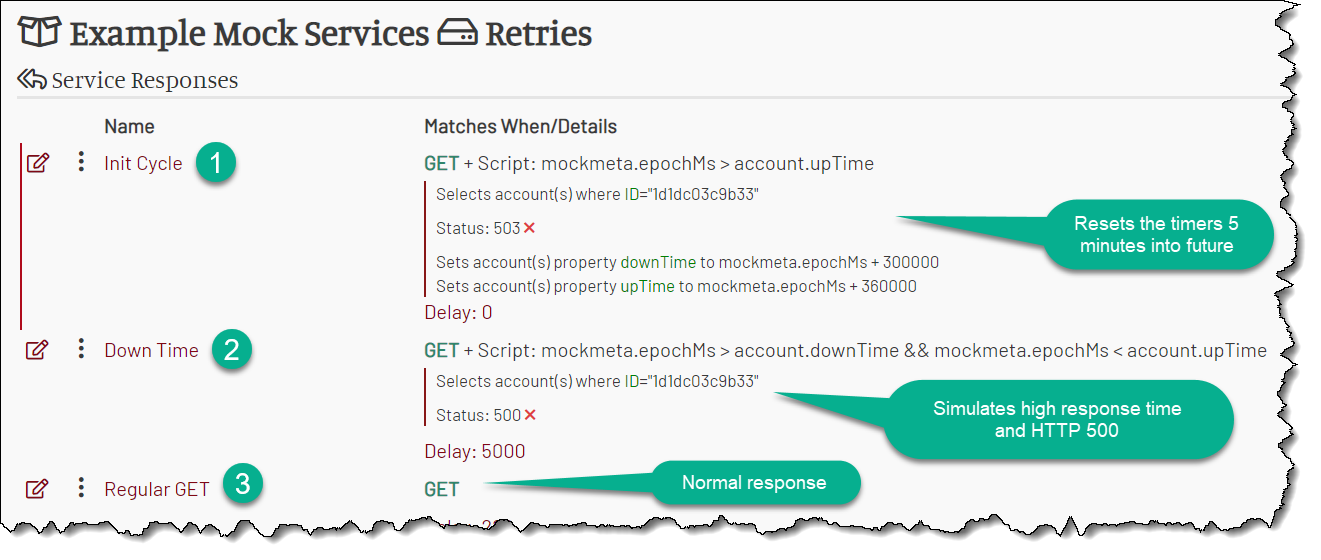
Let’s Review the Service
After everything is done, we should have two guard responses (Init Cyle and Down Time) placed first in the list as guards, and then any number of regular business responses, like below:
Test Time!
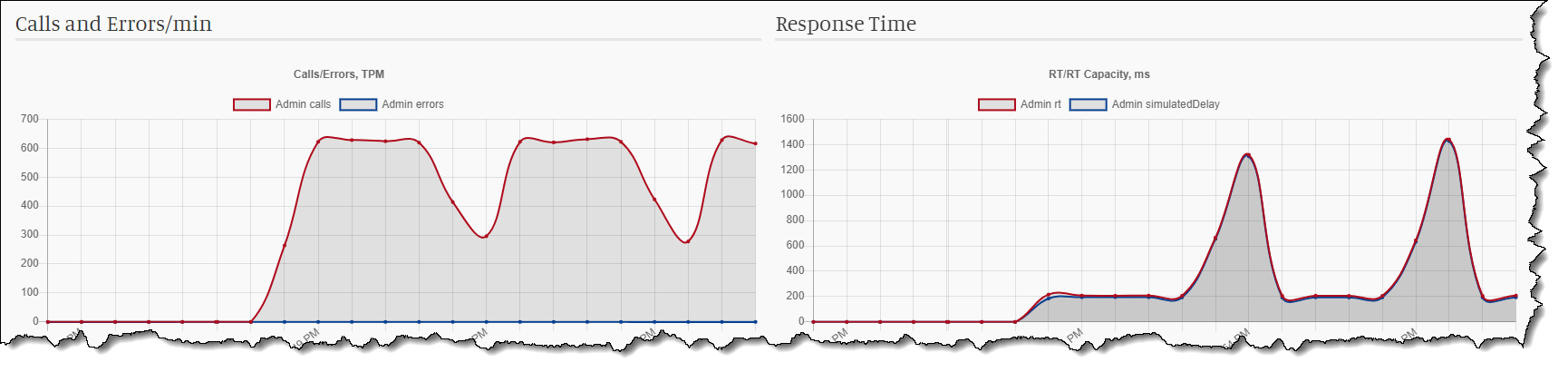
Now we can test it. You should see the familiar repeating high RT pattern.
The number of inbound calls would also fluctuate inverse to the RT - the higher the RT, the fewer calls can go through.
AI created no part of this text. It isn't the Butlerian Jihad, but it is something anyone could do.